Seed-Coder是字节跳动推出的创新开源代码大模型,其核心突破在于实现了训练数据的自动化构建流程。该模型系列规模达80亿参数,涵盖基础版、指令微调版和推理增强版三大变体,在各类编程任务中展现出卓越性能。
传统代码模型依赖人工规则构建训练数据,而Seed-Coder通过大语言模型技术大幅减少了预处理阶段的人力投入。该模型采用透明化架构设计,完整公开其数据流水线细节,能够从GitHub等多元代码源智能筛选优质训练样本,在保证数据质量的同时最大限度降低人工干预。
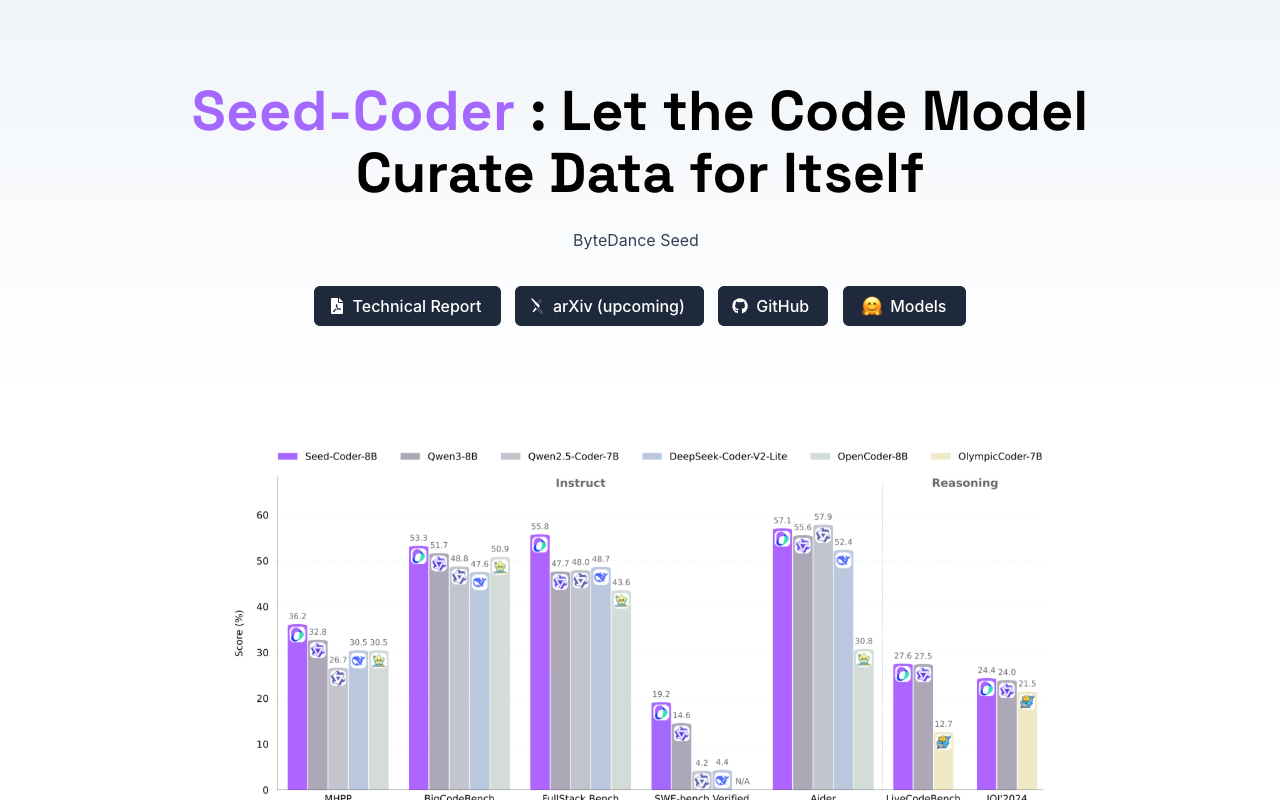
在基准测试中,Seed-Coder的表现超越众多同规模模型,尤其在复杂软件工程任务解决方面优势明显。其中指令微调版在预设工作流和全自动编程场景中表现优异,推理增强版则在竞争性编程领域展现出强大实力。这一技术突破不仅提升了代码模型的智能水平,更推动了大语言模型在代码筛选和评分方面的应用边界,为开源社区带来全新的发展动力。
Seed-Coder is an innovative open-source code model developed by ByteDance, designed to automate the process of curating its own training data. This powerful model family operates at the 8B scale and includes base, instruct, and reasoning variants, showcasing remarkable performance across various coding tasks. By utilizing large language models (LLMs) instead of traditional hand-crafted rules, Seed-Coder minimizes the manual effort required for pretraining data construction.
The model’s architecture emphasizes transparency by providing detailed insights into its data pipeline. Seed-Coder effectively curates code from diverse sources such as GitHub, ensuring high-quality training data with minimal human intervention. This approach not only enhances the coding capabilities of the model but also promotes the evolution of open-source LLMs, showcasing the potential of LLMs in filtering and scoring code data.
Seed-Coder’s benchmark performance indicates that it surpasses many comparable models in solving complex software engineering tasks. Its instruct variant excels in predefined workflows and fully autonomous coding scenarios, while its reasoning variant demonstrates strong capabilities in competitive programming. As Seed-Coder continues to drive advances in code intelligence, it is set to empower a broader range of applications within the open-source LLM community.
You can learn more by visiting Seed-Coder .
相关推荐: 原创内容守护神?AI查重工具Been Posted?助你告别重复发布,打造独特内容策略
在内容为王的数字时代,保持原创性是所有创作者面临的巨大挑战。AI驱动的创新工具“Been Posted?”应运而生,旨在成为内容创作者的得力助手。这款工具的核心功能在于通过先进算法,智能分析用户既有的内容库与新创作的想法,不仅能检测完全相同的文字副本,更能深入…